初心者の方へ
下の説明を読むのが面倒なら次のように設定を変更すれば
わずらわしい思いはしなくてもよくなります。
また、下の設定をすればLPCTSTRとか訳の分からないものはconst char *と同じ意味になり、
自分でコードを書く時にも_T("") などと書く必要もなくなります。
VisualStudio2005での設定例(2003や2008でもほとんど同じです):
プロジェクト名で右クリックしてプロパティを選択
(ここでは太文字でcppTestと書いてあるやつ)

左側のツリーで構成プロパティ→全般を選択するとこのようなものが出てくる。
デフォルトでは文字セットのところが『Unicode 文字セットを使用する』となっているはず。
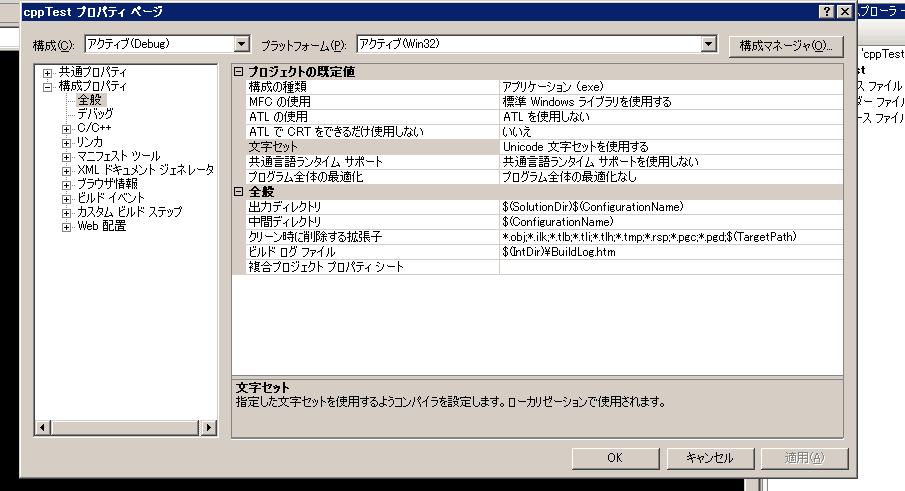
これを『マルチバイト文字セットを使用する』に変更してOKを押すと設定完了。

上級者向けの説明
おそらくVisual Studio2005から初心者を最大に悩ませる罠が
マルチバイト(MBCS)とユニコード(wchar_t)の相違点でしょう。
Visual Studio2003までは標準設定がマルチバイトだったのでWindowsAPIや
DirectX用の関数の引数に文字列を受け渡す時は
TestFunc("文字列");
みたいな感じでオッケーでした。
しかし、Visual Studio2005からはこれではダメなんです。
標準設定がユニコード設定なので多くの関数において文字列は
TestFunc( L"文字列" );
TestFunc( _T("文字列") );
TestFunc( _TEXT("文字列") );
のいずれかで受け渡さなないとダメです。
一番上のL"文字列"はユニコード限定の文字列ですよ、という
意味を表すマクロなので設定をマルチバイトに変更するとエラーになります。
_Tマクロはユニコード設定とマルチバイト設定の差異を解消するためのマクロで
ユニコード設定ならL"文字列"として展開し、 マルチバイト設定なら従来どおり"文字列"とLは付加せずに展開されます。
_Tと_TEXTは同じマクロなので通常は短い_Tが使われます。
ちなみにLはLiteral(リテラル)の略で文字通りのとかいう意味です。
そもそもマルチバイトだのユニコードだのって何?
今までANSIの標準Cで制定されていた文字格納用の型であるcharは
アルファベットや数値などを1byte文字として一つの変数に格納していました。
そのためアルファベット26文字を格納するには
char Alpha[ 26 ] = "abcdefghijklmnopqrstuvwxyz";
などの領域を作ればOKでした。
しかし例えば「あいうえお」という5文字の2Byte文字である平仮名をchar型の変数で格納しようとすると
char Hiragana[ 10 ] = "あいうえお";
として2倍の領域を確保する必要がありました。
もちろん文字列の特定の領域にアクセスするのも非常に面倒です。
上のアルファベットの例だと例えば Alpha[ 1 ]とすれば b に、Alpha[ 2 ]とすれば c にアクセスできるのに
下のひらがなの例だとchar2つ分の領域で1文字を表しているので一々アドレスを渡さないとアクセスすら出来ないのです。
そこで登場したのがwchar_t型(WindowsではWCHARとしても同じ意味)です。
これはアルファベットだろうと日本語のような2byte文字だろうと同じく1つ分の領域で1文字を表すことができます。
WCHAR Hiragana[ 5 ] = L"あいうえお";
と書けば例えば う にアクセスしたいなら Hiragana[ 2 ] とすればいいのです。
まとめ
・マルチバイトとは従来のchar型みたいに1Byte文字と2Byte文字を分けて考える概念のこと
・ユニコードとはWCHAR型の様に日本語や中国語やアルファベットや数値などを区別無く扱う概念のこと
忘れられがちな終端文字の存在
実は先の例のchar Alpha[ 26 ] = "abcdefghijklmnopqrstuvwxyz";は本来は[ 26 ]ではなく
なるべくならAlpha[ 27 ]などと一つ余分に領域を確保すべきです。
なぜかというと『 終端文字 ¥0 』の存在の為です。
C言語ではあらゆる文字列にはその終わりを示す記号があります。それが¥0です。
実は文字列は確保した段階で自動的にそれが挿入されており、文字列を代入する場合はコピー先領域にも
終端文字の為の余分な領域が必要になります。
以下簡単なサンプルです。
char str[ 4 ] = "abc"; //代入する文字列の総バイト数より+1余分に確保(バイト数とは半角英数字を1、日本語などの全角文字を2として足し算した合計)
char str[ 6 ] = "abcde"; //5バイト + 1 = 6
char str[ 7 ] = "あいう"; //6バイト + 1 = 7
char str[ 6 ] = "あabc"; //5バイト + 1 = 6
WCHAR str[ 4 ] = L"abc"; //3文字 + 1 = 4
WCHAR str[ 5 ] = L"あabc"; //4文字 + 1 = 5(WCHARはバイト数ではなく文字数で数える)
WCHAR str[ 6 ] = L"12345"; //5文字 + 1 = 6
(特にVisual Studio 2010からはこうしないと設定によってはエラーになるらしいので一応頭に入れておくと良いでしょう)
マルチバイトとユニコード両方で通用する書き方
ちなみにユニコード設定でもマルチバイト設定でも両方で通用するようにプログラミングするには
char * text = "文字列";
とか
WCHAR * text = L"文字列";
という書き方ではどちらか片方に限定した書き方なのでダメです。
TCHAR * text = _T("文字列");
と書くのが正解です。
また、よくLPCSTRだの何だのがWindowsプログラミングで登場しますがあれの中身は以下の通りです。
| LPCSTR | 中身はconst CHAR * |
| LPCWSTR | 中身はconst WCHAR * |
| LPCTSTR | 中身はconst TCHAR * |
両方で通用する書き方をしたいのならLPCTSTRしかありませんね。
const TCHAR * text = _T("文字列");
と
LPCTSTR text = _T("文字列");
は同じ意味です。
ちなみに中身の英語は
Long Pointer to Constant null-terminated STRing (NULLで終わるロングポインタ固定文字列)
Long Pointer to Constant null-terminated Wide STRing
Long Pointer to Constant null-terminated Template STRing
の略です。
Constantとは宣言後、中身の値が一切変更出来ない変数である事を保証する言葉です。
宣言後に中身を変える必要性があるならLPSTRやLPTSTRなど、C を外して使います。
TemplateとはC++のテンプレートから来ており、『型の変化に適応する』という意味が入っています。
文字列のコピーはどうやるの?
問題があります。strcpyやsprintfなどです。これらはマルチバイトにのみ対応した関数です。
一応ユニコード対応の関数としてstrcpyにはwcscpyが、sprintfにはswprintfが存在しますが、
それらを使うとマルチバイト設定の時に一々書き直さないといけません。
そこで文字列操作関数にもTCHARに対応した関数が用意されています。
両対応の関数を積極的に使うようにしましょう。
| マルチバイト | ユニコード | 両対応 | 効果 |
| strcpy | wcscpy | _tcscpy | 文字列をコピー |
| strncpy |
wcsncpy |
_tcsncpy | 指定文字数分だけ文字列をコピー |
| strcat | wcscat | _tcscat | 2つの文字列を連結 |
| strncat |
wcsncat |
_tcsncat |
2つの文字列を指定文字数分連結 |
| strlen | wcslen | _tcslen | 文字列の文字数を数える |
| strcmp | wcscmp | _tcscmp | 文字列同士を比較し、等しければ0を返す |
| strncmp |
wcsncmp |
_tcsncmp | 指定文字数分だけ文字列同士を比較し、等しければ0を返す |
| strstr | wcsstr | _tcsstr | 文字列の中に指定した文字列が含まれていたら0以外を返す |
| sscanf | swscanf |
_tscanf |
文字列から対応する書式で指定した変数に値を格納 |
| sprintf | swprintf | _stprintf | 文字列変数に対してprintfする(指定の文字列変数に書式文字列を格納) |
| _scprintf | _scwprintf | _sctprintf | 書式文字列をprintfした際の文字数を数える |
| strtok |
wcstok |
_tcstok | 区切り文字を指定し、文字列から区切り文字ごとに文字列を抽出していく |
| strchr | wcschr |
_tcschr |
文字列内から指定の文字を探索し、その位置を返す |
| _strdup |
_wcsdup |
_tcsdup |
文字列の領域を複製(主に文字列を返す関数で応用可能) |
尚、printfやC++のcout、fprintfなどの標準入出力にももちろんマルチバイトとユニコード、
あるいはその両方に対応した関数が存在します。
| マルチバイト | ユニコード | 両対応 | 効果 |
| printf | wprintf | _tprintf | DOS上に文字列を描画 |
| scanf |
wscanf |
_tscanf | DOS上で入力を指定の変数に格納 |
| std::cout | std::wcout | 存在しない | DOS上に文字列を描画 |
| std::cin |
std::wcin |
存在しない |
DOS上で入力を指定の変数に格納 |
| fopen | _wfopen | _tfopen | ファイルストリームを開く |
| fprintf | fwprintf | _ftprintf | 指定のファイルストリームに書式付文字列を書き込む |
| fputs | fputws |
_fputts |
指定のファイルストリームに文字列を一行書き込む |
| fgets | fgetws | _fgetts | 指定のファイルストリームから文字列を一行、指定の変数に読み込む |
| fscanf |
fwscanf |
_ftscanf | ファイルストリームから対応する書式で指定した変数に値を格納 |
両対応がない時は自分で作る
上の表を見て分かる通り、マルチバイトのstd::coutやユニコードのstd::wcoutはしっかりと存在しています。
が、残念なことに両対応のstd::tcoutなどは存在しません。そこでマクロを利用し自分で作ってみましょう。
ユニコード設定の時は_UNICODEが自動的に定義されるのでそれを利用するのが簡単です。
以下のように定義すると、設定に応じ自動的にどちらを使うかを選んでくれるようになります。
|
// tcoutを定義 #if defined(UNICODE) || defined(_UNICODE) #define tcout std::wcout #else #define tcout std::cout #endif |
能書きはいいからコードを見せてよ
それでは3タイプのコーディングを紹介しましょう。
// マルチバイトの例
| #include <stdio.h> int main() { char * Text = "マルチバイト文字列"; printf( "%s", Text ); }
|
// ユニコードの例
| #include <stdio.h> #include <windows.h> #include <locale.h> int main() { setlocale( LC_ALL, "Japanese"); //ロケール(地域言語)を日本語でセット WCHAR * Text = L"ユニコード文字列"; wprintf( L"%s", Text ); }
|
// 両対応の例
| #include <stdio.h> #include <windows.h> #include <tchar.h> #include <locale.h> int main() { setlocale( LC_ALL, "Japanese"); //ロケール(地域言語)を日本語でセット TCHAR * Text = _T("開発環境の設定に応じた文字列"); _tprintf( _T("%s"), Text ); }
|
みなさんが戸惑ったのは『setlocale( LC_ALL, "Japanese"); 』の部分でしょう。
ユニコードとはUniversal Codeの略で文字通り世界中の国々の言語をサポートした規格です。
ですから最初にこれから使う言語が何の言語であるかを明確にしておく必要があります。
それをしないと上のコードだと実行結果は???????とかになってしまいます。
特にファイル入出力とコンソールへの入出力の際にユニコードを使うのなら『setlocale』が必須です。
とはいえプログラムの初めに一度だけ呼び出せばOKです。
上の例では実は三つとも設定に関わらずコンパイルできます。
それは引数が直接char *や WCHAR *などで指定されているからです。
しかし、DirectXやWinAPIの関数の引数の大半はchar *やWCHAR *などではなくTCHAR *や
LPCTSTRが使われるものがほとんどです。以下が格好の例でしょう。
// マルチバイトの例(ユニコード設定ではコンパイルできない)
| #include <windows.h> int main() { char * Text = "マルチバイト文字列" MessageBox( NULL, Text, NULL, MB_OK ); }
|
// ユニコードの例(マルチバイト設定ではコンパイルできない)
|
#include <windows.h> int main()
|
// 両対応の例(どちらの設定でもコンパイルできる)
|
#include <windows.h> int main()
|
ユニコード文字列からマルチバイト文字列への変換
関数で受け取ったユニコード文字列をマルチバイト文字列に変換したり、あるいはその逆をしたいことがあります。
WideCharToMultiByte という専用の関数があるのですが、使い方が面倒な割りに小回りが利かないので、
そういう時はマルチバイトであろうとユニコードであろうと代入後に勝手に変換してくれる ATLのCString型 が便利です。
#include <atlstr.h>するだけで使えます。
※無料版のExpressEditionではatlstr.hありません。実は無料版にはこれが無いんです。そこで互換ライブラリを作ってみました。
CString str; ←マルチバイト設定ならchar *の扱いでユニコード設定ならWCHAR *の扱い
CStringA str; ←設定に関わらずマルチバイトのchar *の扱い
CStringW str; ←設定に関わらずユニコードのWCHAR *の扱い
// ユニコード文字列からマルチバイト文字列へ変換して結合するプログラム
|
#include <windows.h>
|
mbStrにユニコード文字列を代入しても自動的にchar *型の変数に変換されます。
ところでMessageBox関数ではなくMessageBoxAという関数を使いました。
実はWindowsAPIやDirectXの関数には関数名〜Aとか関数名〜Wとかいうのが用意されていることがあります。
これは特にLPCTSTR型やTCHAR *の両対応の文字列を受け取れる関数においてマルチバイト設定なら関数名〜Aを呼び出して
ユニコード設定なら関数名〜Wを呼び出す・・・などという仕組みによるものです。
例を挙げるとMessageBox関数はマルチバイト設定なら内部でMessageBoxAを呼び出してユニコード設定ならMessageBoxWを
呼び出します。これを利用してこんなこともできます。
// 設定に応じて呼び出す関数を代えるプログラム
|
#include <windows.h> // メッセージボックスを表示 int main()
|
CString型の危険性(C++ユーザー向きの説明)
ATLのCString型はC++で標準化されたSTLのstring型やwstring型に比べて安全性に問題があります。
普通に使う分にはいいのですが、マルチスレッドの際に同時アクセスがあることを想定していない型なので
そういう環境ではいきなりPCがクラッシュしてしまう可能性もあります。
実際3Dエンジンの開発中にclass内部の変数にCString型を多用していてブルースクリーンを頻発して泣いていたら
CString型が犯人だと分かりstring型に置き換えたらにピタリと症状が治まったこともありました。
classやtypedefのメンバ変数にCString型を宣言するのは控えた方がいいでしょう。
STLのstring型やwstring型は利便性においてはCString型にあるマルチバイトとユニコードの相互変換機能が無い分劣りますが、
Windows環境ではスレッドセーフが保証されている為classやtypedef内の変数に宣言するのに向いています。
マルチスレッドで文字列を扱う際にはstring型かwstring型を使いましょう。
CString型はマルチバイトとユニコードの相互変換に一時的に使うのに向いていると言えるでしょう。以下にサンプルを示します。
// CString型を介してマルチバイト文字列をwstring型に格納
| #include <iostream> #include <atlstr.h> #include <windows.h> #include <tchar.h> using namespace std; int main() { wstring wideString = L"ユニコード文字列"; CStringW wideString2 = "マルチバイト文字列"; wideString += wideString2; MessageBox( NULL, wideString.c_str(), NULL, MB_OK ); }
|
C++のSTLに精通した方には常識でしょうが一つだけ注意して欲しいのはwstring型の変数から通常のWCHAR *型を取り出すには
変数名.c_str()とする必要があることです。これはstring型の変数からchar *型を取り出したいときにも同様にする必要があります。
戻る






